여러 API에서 제공하는 함수를 사용할때 매개변수를 문자열이나 단일문자로 인자값을 넣을때 함수의 자료값을 보고 멀티바이트인지 유니코드인지 헷갈릴때가 종종 생겨서 내가 정리하는겸 만들었다. 내용은 정말 간략하게 정리했다.
틀린 내용이 있거나 알고있으면 좋은 정보가 있으면 댓글 부탁드립니다.
문자집합(Character Set) 정의
문자 집합은 정보를 표현하기 위한 글자나 기호들의 집합을 정의한 것
문자나 기호의 집합을 컴퓨터에 저장하거나 통신에 사용할 모적으로 부호화 하는 것을 문자인코딩(부호화)이라
하고 인코딩 된 문자부호(Character Set)를 다시 디코딩(복호화)하여본래 문자나 기호로 표현 할 수 있습니다.
문자의 크기(Size)
8bit = 1byte
Char 단일문자 자료형 크기가 1byte (0~ 255)다.
아스키 코드 1Byte
영어,숫자 등등 (반각문자) 1Byte
한글,일본어 등등 (전각문자) 2Byte
중국어 같은경우 획수가 많은건 3Byte도 있지만 그런건 예외이기 떄문에 위에 내용만 알고있으면 된다.
ASCII(아스키코드)

ASCII(American Standeard Code for Information Interchage) 의 약자다.
아스키 코드표는 용량이 1byte이지만
실제로 7bit까지만 써서 0~127(2^7)의 숫자를 나타낸다.
그리고 아스키코드 이후에 ISO/IEC 8859-1, ISO/IEC 8859-N 문자집합의 등장으로
기존 아스키코드 0~127은 그대로 사용하고 8bit까지 추가로 사용하게되며 128 ~ 255(2^8) 영역까지 사용하여 서유럽어에서 필요로 하는 문자와 몇가지 특수문자를 추가했다한다.
MultiByte(멀티바이트)
MBCS(Multy Byte Character Set) 의 약자이며 가변 너비 인코딩이라고한다.
다국어를 표한하기 위해 사용했던 방식의 문자 집합중 하나
문자의 크기에서 영어,숫자는 1byte 한국어,일본어는 2byte라고 소개했는데 이 부분을 해결해주는것이 멀티바이트 문자집합이다.
간단히 말해서 입력값으로 들어오는 단일문자나 문자열을 자동으로 문자 종류에 따라 byte를 지정해주는 것이다.
BOOL TextOut(HDC hdc, int nXStart, int nYStart, LPCTSTR lpString, int cbString);
//(hdc,x 좌표 , y 좌표, 문자열 , 문자열 길이)
//매크로 함수이며 문자열인자값을 무엇을 넣는냐에 따라 그에 맞는 함수가 호출된다.
//인자값 : 멀티바이트 문자열(LPCSTR)
BOOL TextOutA( _In_ HDC hdc, _In_ int x, _In_ int y, _In_reads_(c) LPCSTR lpString, _In_ int c);
//멀티바이트 문자나 문자열을 사용시 함수명뒤에 A가 붙는다.
UniCode(유니코드)
Universal Coded Character Set의 약자이며, 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다.
위에서 설명한 문자의 크기가 언어 종류에 따라 달랐는데 유니코드는 이런 가변적인 특성을 없애고 모든 문자를 2byte로 표현하기 위해 정의한 방식이다. 즉, 모든 문자를 2byte로 일관되게 지정하고 사용한다는것이다.
BOOL TextOut(HDC hdc, int nXStart, int nYStart, LPCTSTR lpString, int cbString);
//(hdc,x 좌표 , y 좌표, 문자열 , 문자열 길이)
//매크로 함수이며 문자열인자값을 무엇을 넣는냐에 따라 그에 맞는 함수가 호출된다.
//인자값 : 유니코드 문자열(LPCWSTR)
BOOL TextOutW( _In_ HDC hdc, _In_ int x, _In_ int y, _In_reads_(c) LPCWSTR lpString, _In_ int c);
//유니코드는 함수명뒤에 W(wide)를 붙인다. 또한 자료형에 W를 추가한다.(LPCWSTR)
//멀티바이트 문자열을 대입할때 "ABC123가나다" 이렇게 따옴표 안에 내용을 넣어서 사용한다.
//유니코드는 문자열 앞에 L을 추가하고 내용을 적는다. ex) L"ABC123가나다"
문자 집합에 따른 문자열 길이 계산시 유의사항
char* Ch = "멀티1234"; //멀티바이트 문자열 초기화
wchar_t* wCh = "유니1234" //유니코드 문자열 초기화
int len_Multi = strlen(Ch); //멀티바이트 문자열 길이 리턴
int size_Multi = sizeof(char) * Ch; //멀티바이트 문자열 크기 리턴
int len_Uni = strlen(wCh); //유니코드 문자열 길이 리턴
int size_Uni = sizeof(wchar_t) * wCh; //유니코드 문자열 크기 리턴
/* 결과값 */
// len_Multi = 8 : 한글은 (2글자 * 2byte), 숫자는 (4글자 * 1byte), 총 8글자.
// size_Multi = 8 : 한글은 2byte로 취급,숫자는 1byte취급 ,총 8byte.
// len_Uni = 6 : 유니코드는 전부 2byte로 취급, 전부 1글자 취급 ,총 6글자
// size_Uni = 12 : 유니코드는 전부 2byte로 취급(6글자 * 2byte), 총 12글자
//p.s 멀티바이트 문자열 계산함수는 _mbslen() 함수를 이용해야 함.
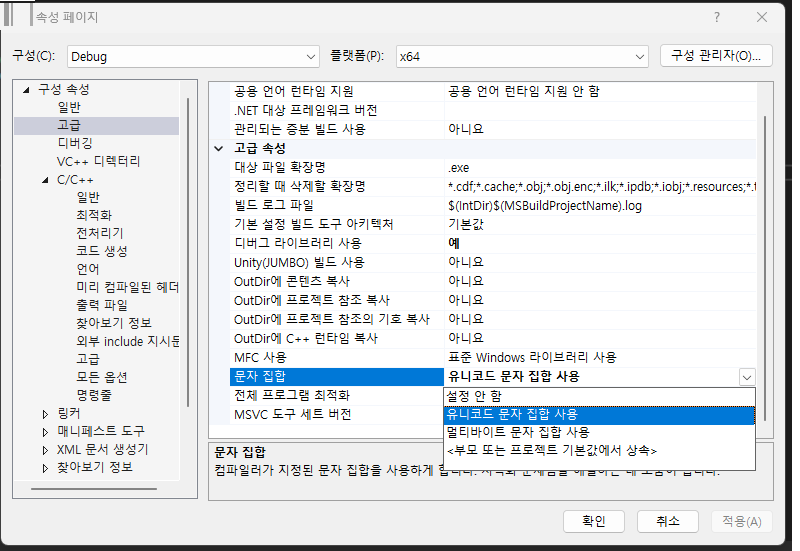
프로젝트의 문자집합 확인 및 변경하기
컴파일러가 지정된 문자집합을 사용하게 하는 설정이다.
프로젝트> 속성 > 구성 속성 > 고급 > 문자 집합 >문자집합 변경
'C++' 카테고리의 다른 글
| unique() (vector의 중복 값 제거) (0) | 2023.06.12 |
|---|---|
| std::vector (reverse_iterator,rbegin(),rend(),역방향반복자,내림차순정렬) (0) | 2023.06.09 |
| STL 범용 수치 알고리즘 (accumulate , inner_product) (0) | 2023.06.09 |